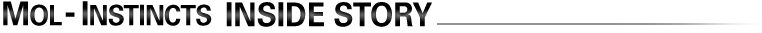Things were not always going well, as does occur in project work. The deadline was coming; we checked the whole process several times and nothing seemed to be wrong. We had no idea what the origin of the problem was.
“What will happen if this project is not completed in time?” We started becoming anxious about our future. What will happen to our reputation? Our jobs? Our families?


As more time passed, feelings of unfairness started to prevail. We had been working day and night all along on our project. Our memories became those of hard times passing through so many tough industrial problems ··· In this era of economic hardship, life doesn’t treat scientists and engineers kindly in general.
In fact, creating a clear deadline for a task in science and engineering is unpredictable. No one knows what will happen without actual trials. Anyway, time is money and the deadline has to be met. But how?


We took our work process apart piece by piece, double checked everything over again. We then accidently realized there were input data factors as this discovery process began: viscosity, thermal conductivity, critical pressure, vapor pressure, etc. These data came from the outside of our work and were supposed to be alright. At that time, it was beyond our conception that these input data can actually cause serious problems.
Digging deep into them for months opened up a new world of truth. We found a large portion of these data were determined by inaccurate estimation methods. Also, a significant portion of them were measured by incorrect experimentation. More surprisingly, no data existed at all in many other industrial applications - the inaccurate estimation methods were again utilized in this case frequently.


We searched the Internet, scientific books, journals, and commercial databases for the missing data - and they all failed. We tried various commercial software programs to come up with estimates - and they too failed. It made sense to try the estimation methods published in the scientific journals - and this failed as well. The experimental measurements were never practical - they are too slow, too expensive, and sometimes not even possible.
We finally failed to meet the deadline and we were left to provide inaccurate records for our customers, not because of our work but because the input data from outside sources were unreliable. Something had to be done - we could not experience the same problems over again. There was only one thing left to be done; "Do something else fully on our own!"
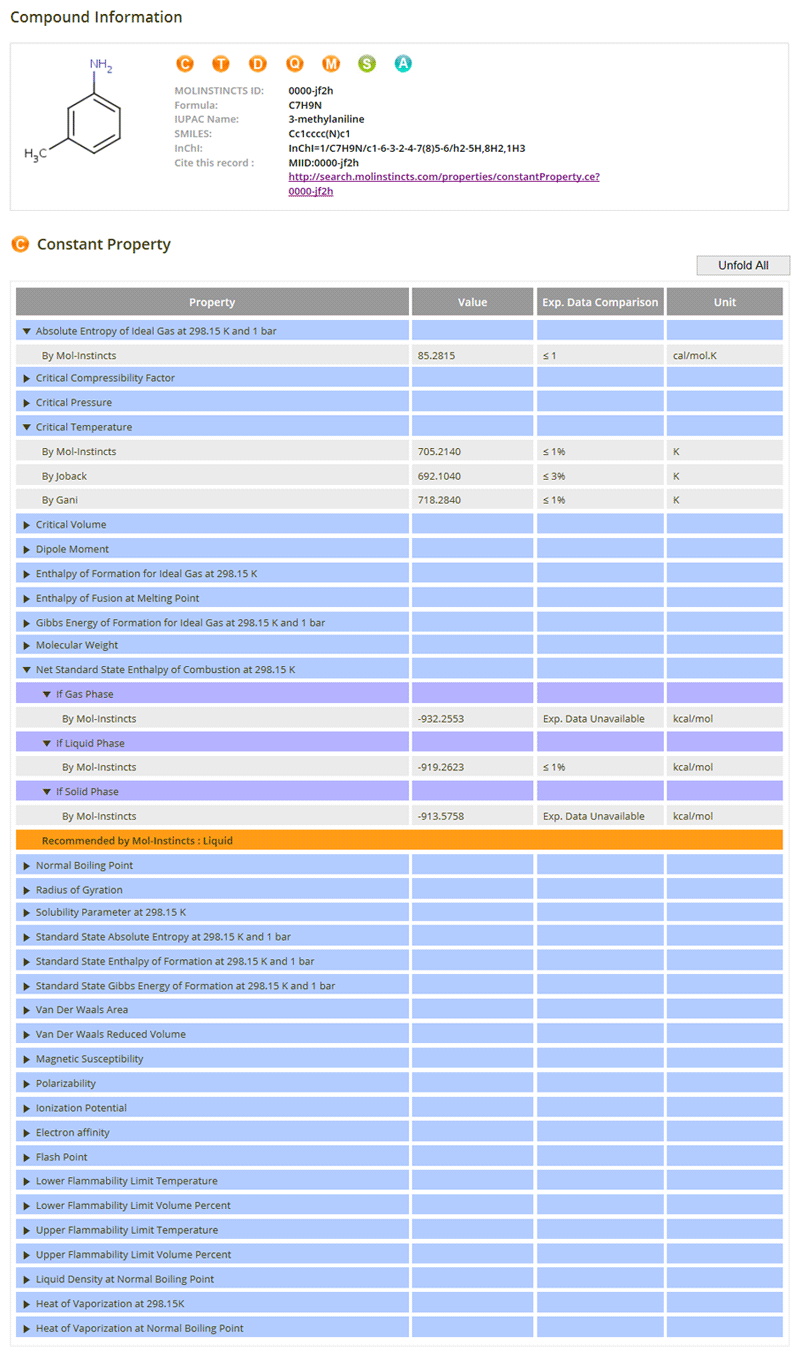
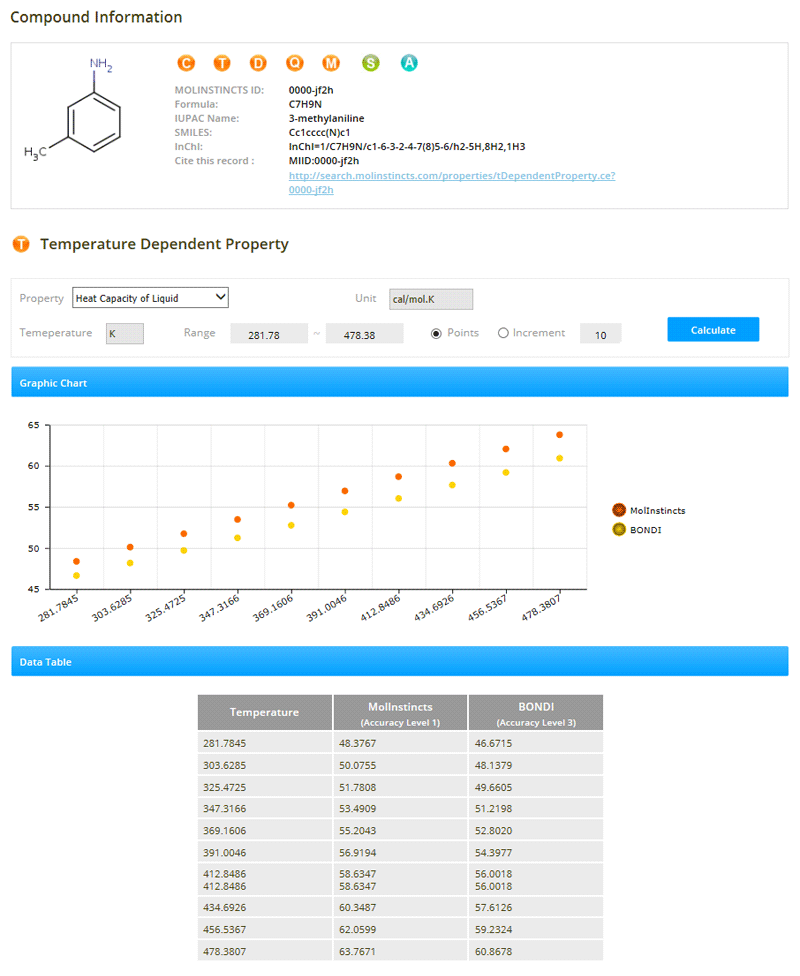
We started look more deeply into the fundamentals of the compounds - at the quantum level. It did not directly provide what we wanted, so we combined the quantum information with fundamental theories. This was still not accurate enough. Modern modeling approaches were therefore combined. Years were then spent verifying the accuracy of our models...


"How about making our solutions available to our fellow scientists and engineers all over the world? After all, we are not alone in having these types of property data problems." Someone on our staff suggested this great idea, but it caused a big argument.
Our estimation technology can be a form of software, so that users can process their desired chemicals themselves. One staff member strongly queried, "Do you want our customers to do the quantum calculations?
Performing these calculations is definitely not for every scientist and engineer, not even for every chemist. It can take from weeks to months to accomplish this work; and the structure optimization does not converge in some cases.
How would they handle the strange numerical errors? How much time do we expect our customers to spend learning how to use our complicated software?"


Members of our staff suggested we calculate and process all information internally and serve only the final results to our customers - this way users will be free from the numerical errors and don't have to wait for the calculations to be finished.
Other staff members were strongly against it.
"What compounds? How do we know which compounds our customers want? Unless we cover millions of compounds, our service will be too limited." Opposite opinions came out and the discussions went on and on...like, "Why not process millions of compounds?" "That's impossible!"...
After days of disputes, we made a decision - we will take care of all the processes and provide only the final outputs. "You guys are crazy!" With that parting shot, many people left the company.


Processing millions of chemical compounds..., this was not something that could have been done manually. We had to automate every step of our estimation processes, including molecule generation, quantum calculation, numerical error handling, descriptor generation, and model estimation. This required the creation of new algorithms and computer programs.
We needed big computing power, so we built our own computing center with more than 2,200 CPU cores. The results produced needed to be organized into a navigable database. This need forced us to develop our own DB server system. Software for data search and navigation also had to be developed for ease of use.
During these developments many talented people newly joined our company, as they were impressed by our challenging projects.
The last challenge came from the CEO. "We have to manually inspect every number and piece of information generated from the computer before serving to our customers.
The value of our services is not only coming from our innovative computation technology, it is also coming from our expertise; therefore a manual 'double check' must be added to ensure the quality of our services." The technical staff responded, "Yeah, right, millions of compounds..." However, nobody left the company this time. Instead, they did the painful work and later developed a semi-automatic process to better support the quality inspection.

Everybody agreed on one thing at the end of the long journey. "We have developed an automatic, systematic process. Now, it is just a matter of time to add more compounds to our database."


























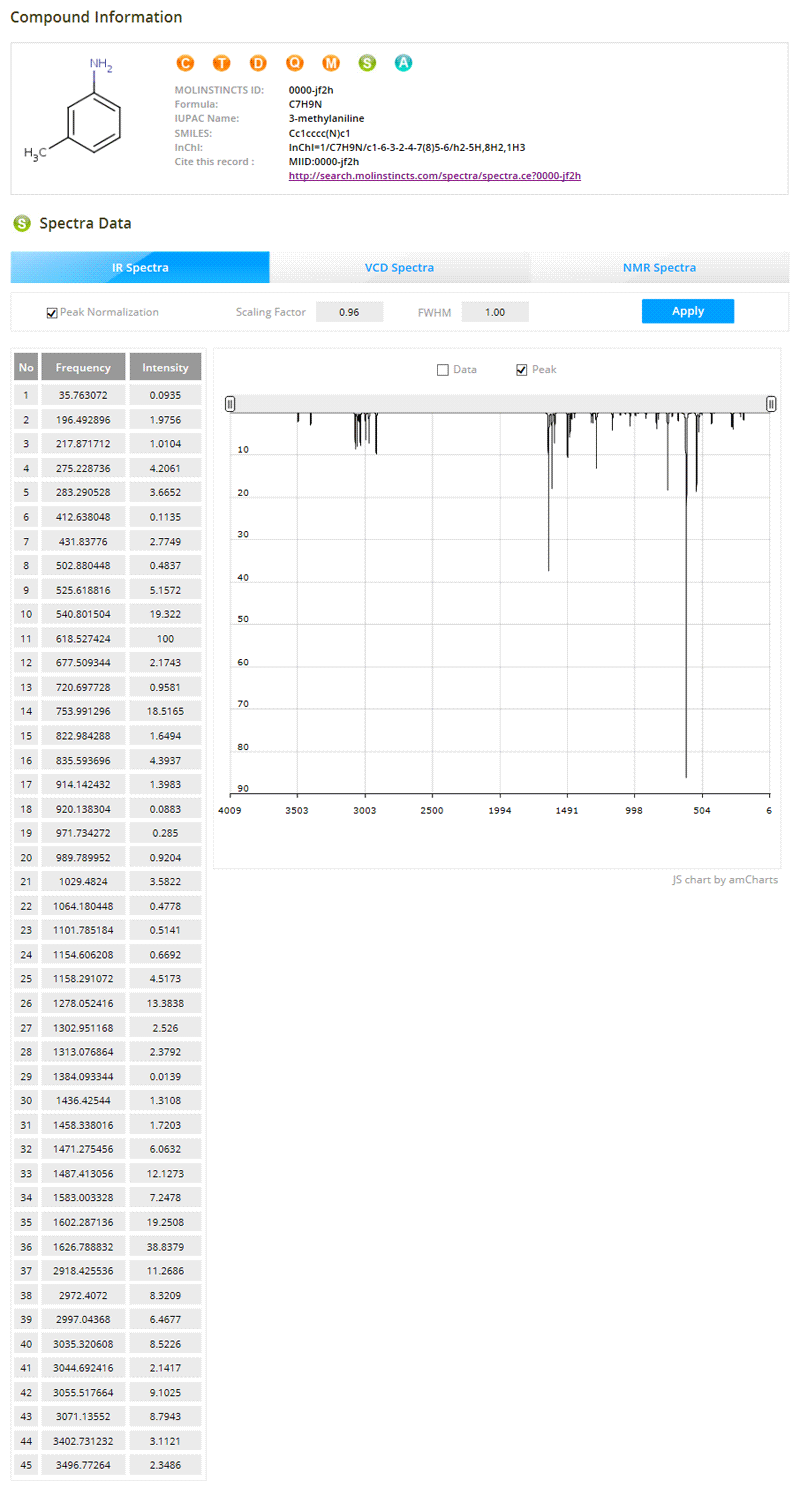
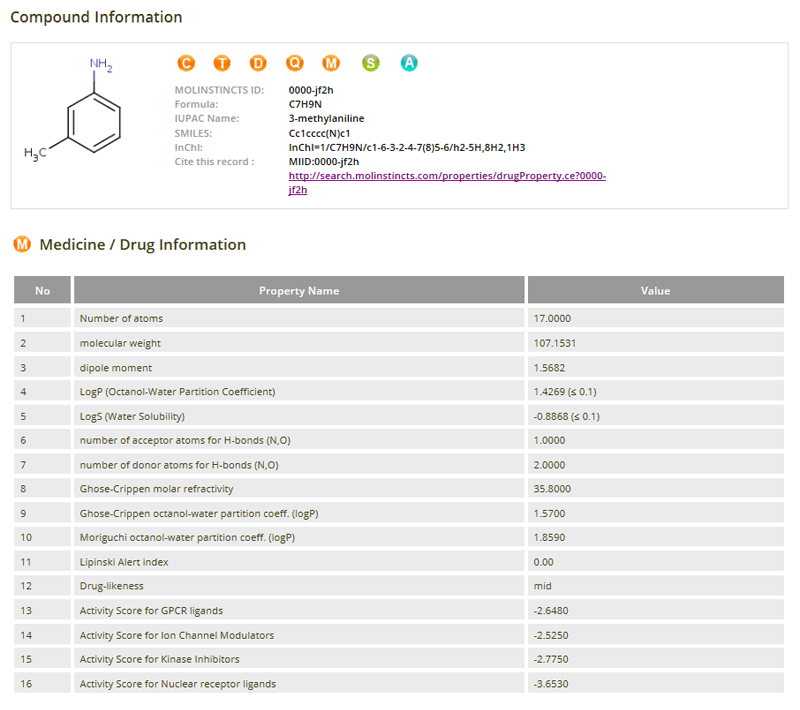
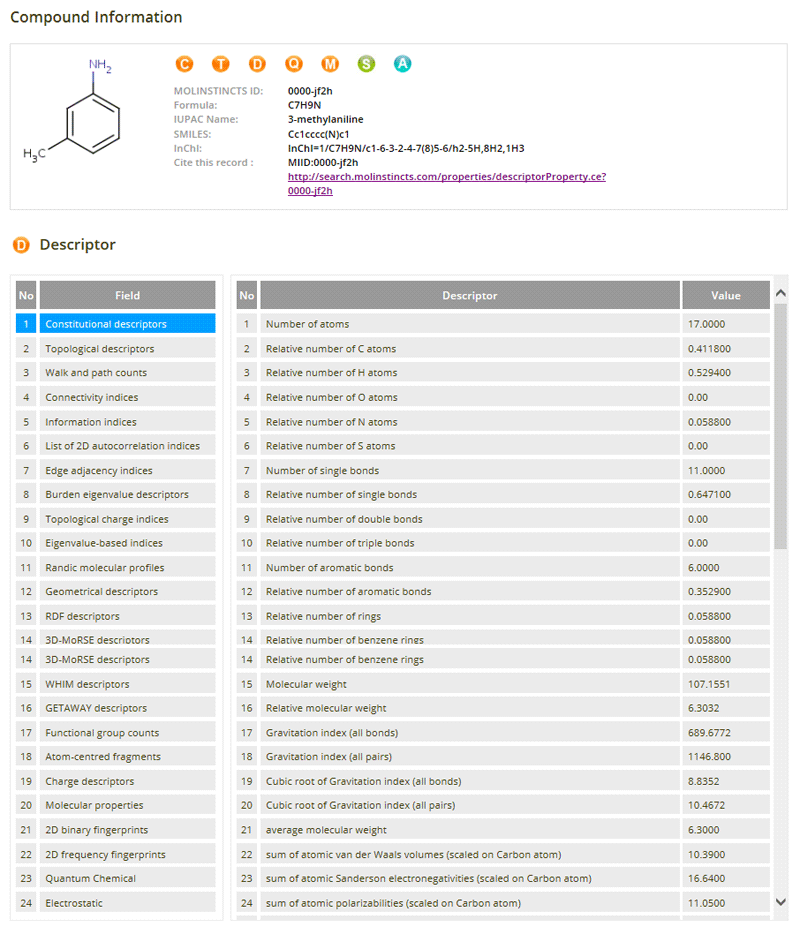
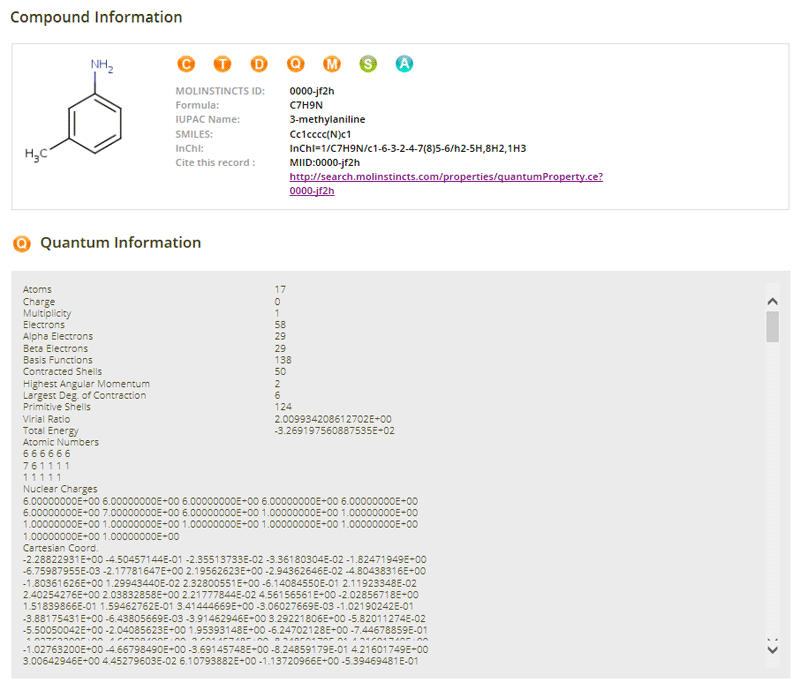




 HOME
HOME